la35.net blog para alumnos de la ET Nº35
Introducción a MIPS

Una introducción a la programación en assembler de MIPS usando SPIM. Todo el código disponible en GitHub.
Contenidos
La arquitectura MIPS
MIPS es una familia de microprocesadores que se remonta a 1985. Con arquitectura nos referimos al lenguaje máquina de un microprocesador, como puede ser x86, ARM o AVR. La arquitectura MIPS tiene versiones de 32 y 64 bits. Ambas versiones fueron evolucionando con el correr del tiempo, agregando o quitando instrucciones y características.
Nosotros vamos a usar un simulador llamado SPIM que implementa el conjunto de instrucciones de MIPS de 32 bits, específicamente las versiones R2000 (1985) y R3000 (1988). SPIM nos permite ejecutar programas escritos en ensamblador para estos procesadores y nos provee de un entorno de ejecución muy básico simulando un sistema operativo mediante la instrucción syscall.
SPIM
Pueden descargar SPIM del sitio oficial, busquen el instalador en formato MSI para Windows. Si están en Linux seguramente pueden encontrar un paquete con el nombre de spim o qtspim dependiendo de su distro.
Para trabajar con SPIM necesitan escribir su código en un archivo de texto y luego abrirlo en el simulador. La tradición indica que los archivos de código en assembler llevan las extensiones .s o .asm.
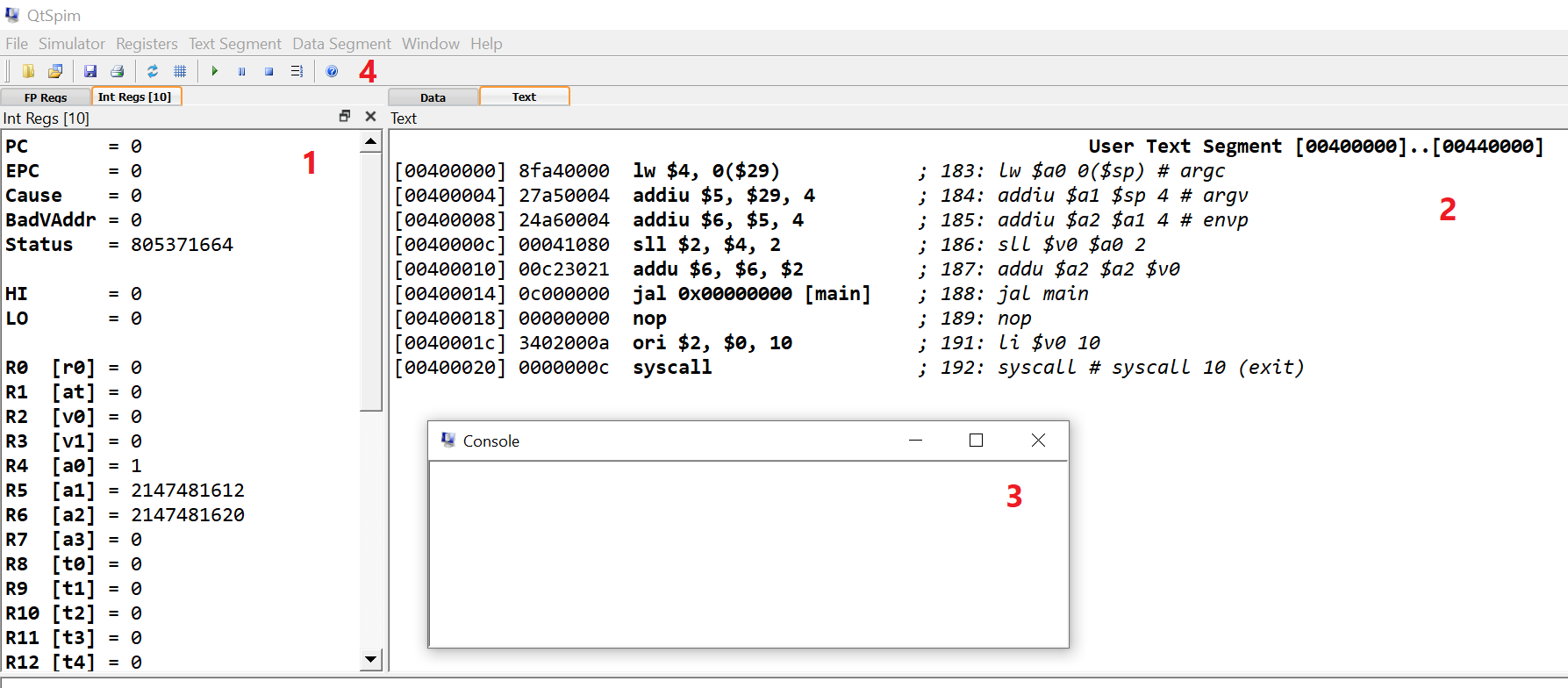
La interfaz de SPIM está dividida en dos paneles. En el panel de la izquierda (1) tenemos los registros, los registros de números enteros en una pestaña y los de coma flotante en otra. Nosotros vamos a utilizar solo los registros enteros. En el panel de la derecha (2) tenemos los contenidos de nuestro archivo de assembler tal como se cargan en la memoria principal. Este panel también se divide en dos pestañas, una para instrucciones del programa o código bajo el nombre de text. Y la otra para datos (la pestaña de data) donde vemos los contenidos de las distintas secciones de datos de nuestro programa tal como aparecen en la memoria.
En una ventana aparte tenemos una consola de texto (3) para interactuar con el programa que estamos ejecutando. Cuando nuestro programa interactúa con el sistema operativo (el del simulador, no el de nuestra computadora) puede utilizar la consola para realizar I/O, básicamente leer o imprimir caracteres en la consola.
Por último en la parte superior tenemos la barra de herramientas (4) donde podemos cargar un archivo de código en el simulador, ejecutarlo, blanquear todos los registros o ejecutar un programa paso a paso entre otras cosas.
Hello world
Vamos a escribir un programa hello world en assembler. Para eso creamos un archivo de texto y lo abrimos en nuestro editor preferido.
$ touch hello.asm
$ atom hello.asm
En el archivo vamos a copiar el siguiente código
.data
hello: .asciiz "Hello world\n" # el string que voy a imprimir
.text
.globl main
main:
li $v0, 4 # syscall print_string code
la $a0, hello # pongo en $a0 la direccion de hello
syscall # print_string syscall
li $v0, 10 # syscall exit code
syscall # exit syscall
Vamos a ver en detalle que es lo que hace cada línea.
Directivas y segmentación de memoria
En lenguaje ensamblador tenemos directivas, en el programa de arriba hay cuatro directivas que le indican al ensamblador (el programa que convierte código ensamblador a lenguaje máquina) alguna acción. La directiva .data indica que lo que sigue va en el segmento llamado static data, o sea a partir de la dirección de memoria 0x10000000. La directiva .asciiz indica que el string Hello world\n es una cadena de caracteres ASCII terminada con el null byte (código 0 en ASCII).
La directiva .text indica que lo que sigue va en el segmento de código de la memoria, desde la dirección 0x00400000 hasta el inicio de static data. Por último .globl indica que una etiqueta es un símbolo global y es accesible por otro archivo de código.
La memoria en MIPS está segmentada entre el nivel del usuario y el nivel del kernel (del sistema operativo). El nivel del usuario está entre 0x00400000 y 0x80000000. El resto de la memoria está reservada para el sistema operativo. Dentro del nivel del usuario tenemos cuatro segmentos. Sus nombres tradicionales en inglés son text, static data, dynamic data o heap y stack.
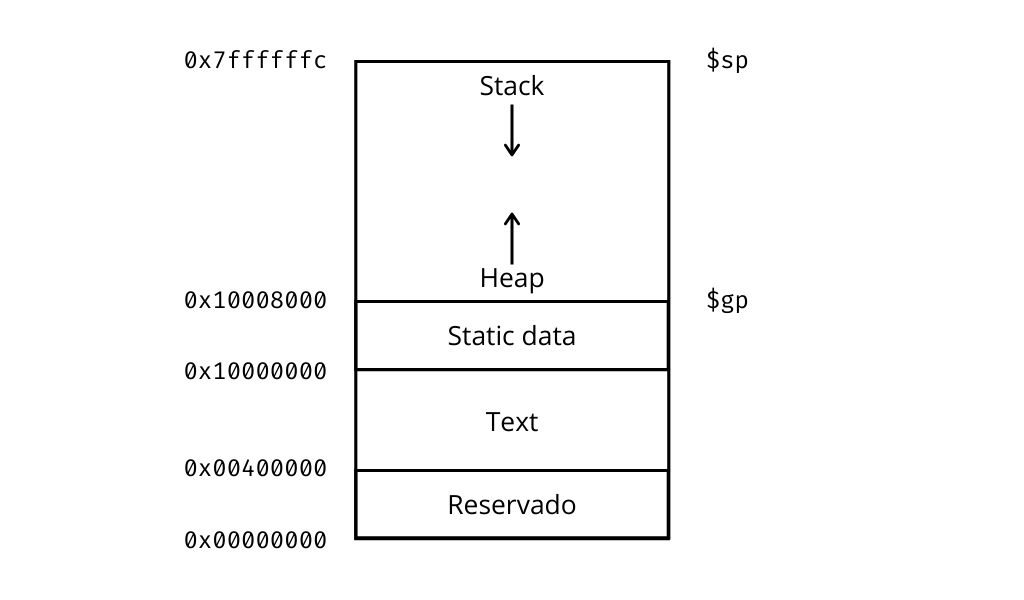
Los segmentos de text y static data son los que contienen el código del programa y las variables o datos que se conocen al momento de compilar el programa.
Los otros dos segmentos contienen datos dinámicos, variables que se crean durante la ejecución del programa. La pila o stack crece desde la dirección de memoria más alta hacia abajo, y el segmento llamado heap desde el final de static data hacia arriba. En casos extremos la pila y el heap podrían colisionar produciéndose lo que se conoce como stack overflow. Ya veremos más adelante como los programas usan estos dos segmentos. En el dibujo de arriba aparecen dos registros especiales que son punteros (apuntan) al inicio de cada uno de estos segmentos: el stack pointer y el global pointer. Una aclaración, en MIPS32 se considera una palabra de memoria a 4 bytes (32 bits), pero la memoria es direccionable por byte. Las instrucciones y los números enteros ocupan 4 bytes, una excepción importante a esto son los caracteres ASCII, que ocupan un byte cada uno.
Etiquetas
Siguiendo con el código de assembler vemos que hay dos palabras que terminan con dos puntos: hello: y main:. Esta es una de las grandes fortalezas de programar en assembler en vez de código máquina, las etiquetas o labels.
Las etiquetas las escribimos siempre sin dejar margen o indentación, y lo único que hacen es marcar o etiquetar una dirección de memoria. Nos ahorran el tedio de tener que escribir 0x10010000 para indicar donde empieza el string “Hello world”. Cuando el programa es ensamblado (traducido a código máquina) todas las referencias a las etiquetas se reemplazan por sus valores numéricos.
Tal como hacemos en C es una convención indicar con la etiqueta main: la función principal donde arranca nuestro programa.
Instrucciones
Por último veamos las instrucciones propiamente dichas del programa. En este sencillo programa hello world usamos solo tres instrucciones distintas:
- Load Immediate o
li: carga una constante en un registro. - Load Address o
la: carga una dirección de memoria usando una etiqueta en un registro. - System Call o
syscall: una llamada de sistema al OS. Le pide al sistema operativo que realice alguna operación, generalmente de I/O según los valores de ciertos registros.
Aclaración importante, li y la no son instrucciones reales de MIPS32. Son pseudoinstrucciones, es decir que el ensamblador nos provee de instrucciones que no existen en la CPU pero que se pueden expresar con instrucciones de la CPU. Esto es una comodidad para hacer más fácil de entender el código. Por ejemplo la primer instrucción li $v0, 4 en realidad se ejecuta con ori $2, $0, 4 que es un or immediate. Y peor aún, en lenguaje máquina se escribe 0x34020004. Vemos que un ensamblador nos hace la vida mucho más fácil.
System calls
La otra instrucción que aparece es syscall que sirve para pedirle alguna operación o servicio al sistema operativo. Antes de usar syscall tenemos que cargar un código numérico en el registro $v0 y en algunos casos poner un valor en $a0 como argumento. La siguiente tabla resume los códigos más comunes que vamos a utilizar.
| Código | Servicio | Argumentos | Resultado |
|---|---|---|---|
| 1 | print int |
valor en $a0 |
|
| 4 | print string |
dirección del string en $a0 |
|
| 5 | read int |
valor leído en $v0 |
|
| 10 | exit |
En el programa de arriba usamos el código 4 para imprimir “Hello world” a la consola y el código 10 para terminar el programa.
Registros
Los símbolos que empiezan con el signo $ en el programa son registros. Hay 32 registros enteros en MIPS numerados del 0 al 31. El registro 0 siempre vale cero. Los registros reciben nombres por el uso que se les da convencionalmente aunque en realidad excepto por el registro zero todos los registros son de propósito general, es decir podemos usarlos al programar. El contador de programa no está incluído en esta lista de 32 registros.
| Nombre | Número | Uso |
|---|---|---|
| zero | 0 | Constante 0 |
| at | 1 | Reservado para el ensamblador |
| v0 - v1 | 2 - 3 | Resultados de funciones |
| a0 - a3 | 4 - 7 | Argumentos de funciones |
| t0 - t9 | 8 - 15, 24, 25 | Registros temporarios |
| s0 - s7 | 16 - 23 | Registros guardados |
| k0 - k1 | 26 - 27 | Registros del kernel |
| gp | 28 | Global pointer |
| sp | 29 | Stack pointer |
| fp | 30 | Frame pointer |
| ra | 31 | Return address |
A medida que avancemos con los ejemplos de MIPS vamos a ver el uso que se le da a cada registro o grupo de registros.
Otro ejemplo
Como segundo ejemplo tenemos un programa que suma dos números de la memoria y muestra el resultado en la consola.
.data
numbers: .word 32, 68 # reservo dos words y le doy valores
.text
.globl main
main:
la $t0, numbers # guardo en $t0 la direccion de numbers
lw $t1, 0($t0) # guardo en $t1 el 32
lw $t2, 4($t0) # guardo en $t2 el 68
add $t1, $t1, $t2 # sumo $t1 = $t1 + $t2
li $v0, 1 # syscall print_int code
move $a0, $t1 # muevo el resultado ($t1) a $a0 para la syscall
syscall # print_int syscall
li $v0, 10 # syscall exit code
syscall # exit syscall
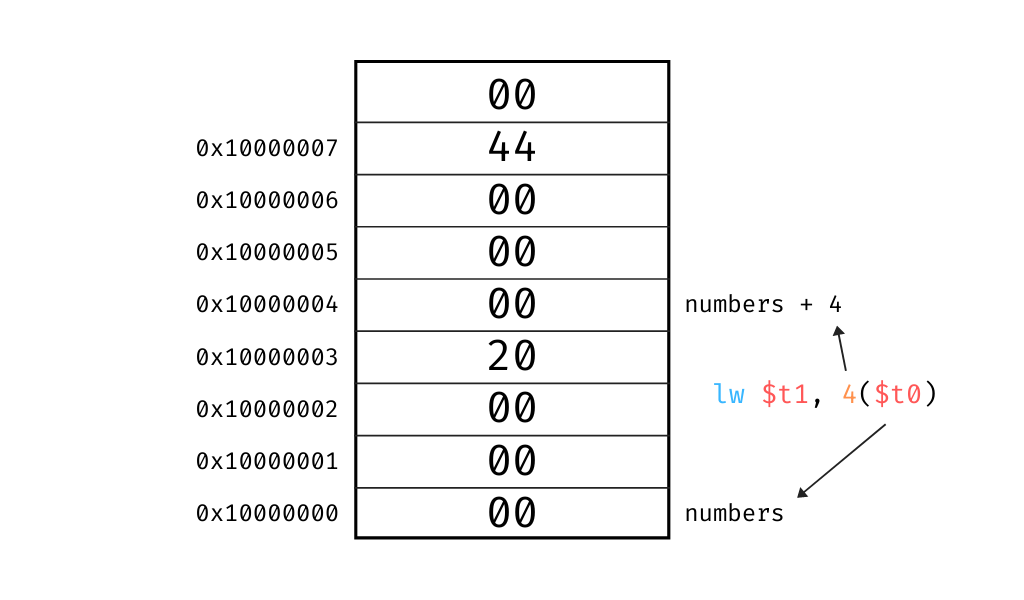
Lo primero que vemos es una etiqueta numbers: y la directiva .word. Esta directiva indica que lo que sigue es una palabra o memory word. En MIPS32 una palabra son 32 bits o 4 bytes. Así que a partir de la dirección a la que apunta numbers: tenemos 8 bytes. Los primeros 4 bytes representan el número 32 y los próximos 4 bytes el número 68, porque los números enteros son representados con 32 bits.
Luego en main: tenemos que cargar esos números en dos registros: $t1 y $t2 porque MIPS es una arquitectura del tipo load/store, es decir que la ALU solo opera con valores en los registros, nunca directamente con la memoria. El uso de lw (load word) en MIPS requiere primero el registro donde vamos a guardar la palabra de memoria y un registro base (un puntero a una dirección de memoria). El segundo argumento de lw, la parte de 0($t0) indica el registro base y un offset. El primer load word carga en $t1 los 4 bytes a partir de la dirección contenida en $t0 que es la misma que la de numbers: más 0 bytes. En el segundo load word necesitamos los próximos 4 bytes, por eso escribimos 4($t0). O sea lo que valga $t0 más 4. Si no entendiste nada, una imagen vale más que mil palabras.
La instrucción add realiza la suma aritmética del segundo y el tercer registro y guarda el resultado en el primero. Por último usamos syscall con código 1 para imprimir un entero en la consola. Además de cargar el 1 en $v0 tenemos que cargar el número a imprimir en $a0, lo podemos hacer copiando el valor de $t1 a $a0 usando la pseudoinstrucción move.
Último ejemplo
¿Y si queremos que los dos números a sumar los ingrese el usuario? Bueno el último ejemplo hace exactamente eso.
.data
prompt: .asciiz "Ingrese un numero\n" # prompt string
msg: .asciiz "La suma es " # msg string
.text
.globl main
main:
li $v0, 4 # syscall print_string code
la $a0, prompt # cargo la direccion del string en a0
syscall # imprimo el prompt
li $v0, 5 # syscall read_int code
syscall # leo el primer numero
move $t1, $v0 # muevo el resultado de la syscall a t1
li $v0, 4 # syscall print_string code
la $a0, prompt # cargo la direccion del string en a0
syscall # imprimo el prompt
li $v0, 5 # syscall read_int code
syscall # leo el segundo numero
move $t2, $v0 # muevo el resultado de la syscall a t2
add $t3, $t1, $t2 # sumo los dos números y pongo el resultado en t3
li $v0, 4 # syscall print_string code
la $a0, msg # cargo la direccion del string en a0
syscall # imprimo el mensaje
li $v0, 1 # syscall print_int code
move $a0, $t3 # muevo el resultado ($t3) a $a0 para la syscall
syscall # print_int syscall
li $v0, 10 # syscall exit code
syscall # exit syscall
Si copian este código a un archivo y lo abren en SPIM, al ejecutarlo pueden interactuar con la consola para ingresar los dos números. El programa no agrega nada que no haya aparecido en los dos ejemplos anteriores.
Si prestaron atención al código de los tres ejemplos habrán notado la cantidad de comentarios (el # delimita comentarios). Esto es bastante común al programar en assembler porque las instrucciones son bastante generales o crípticas. Traten de escribir un comentario para cada línea de código o corran el riesgo de no entender su propio código dentro de dos horas.
Para terminar les dejo el link a la “Green Card” de MIPS que sería el machete oficial para el programador de MIPS.
Escrito el 13 de Agosto de 2020 por Santiago Trini